 Describing
Objects by their Attributes
Describing
Objects by their Attributes
My primary research goal is to model the physical and semantic structure of the world, so that computers can better understand scenes from images. A good visual system should interpet images in terms of a physical space where objects interact.
Our research focuses on modeling relations among objects, categories, and surfaces, so that the computer gradually becomes better at learning, predicting, and describing.

Improve generalization, robustness to unfamiliarity, and scalability of recognition by modeling objects in terms of their properties.

Recover a spatial layout of the scene and its objects from an image.

Interpret objects and their interactions within the physical space of the scene.
Describing
Objects by their Attributes
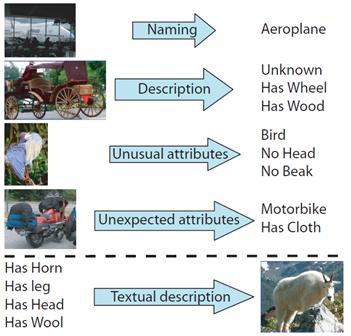
We shift the goal of recognition from naming to describing. By considering an attribute based representation, we are able to say more about familiar objects and gain information about unfamiliar objects. We introduce a new dataset for learning and evaluating attribute classifiers, which is available for download.
 Recovering the Spatial Layout of Indoor Scenes
Recovering the Spatial Layout of Indoor Scenes
We consider the problem of recovering the spatial layout of cluttered indoor scenes from monocular images. We gain robustness to clutter by modeling the global room space with a parameteric 3D “box” and by iteratively localizing clutter and refitting the box. Our dataset is available for download.
 Closing
the Loop on Scene Interpretation
Closing
the Loop on Scene Interpretation
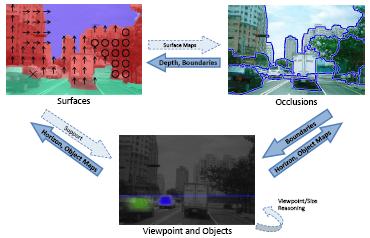
We model the interactions among occlusion, surface, object, and viewpoint inference, leading to modest quantitative and more substantial qualitative improvements. We also extend Automatic Photo Pop-up with occlusion, object, and viewpoint information, leading to more robust and detailed models. Finding more robust and flexible models for integrating diverse and numerous inference processes is a long-term interest.
 Recovering Occlusion Boundaries from a
Single Image
Recovering Occlusion Boundaries from a
Single Image
We recover occlusion boundaries and figure/ground labels by reasoning about region similarity, 3D geometry, boundaries, and junctions. Code is available.
 Putting Objects in Perspective
Putting Objects in Perspective
We propose a method for modeling objects, viewpoint, and surfaces in an integrated fashion. With a simple belief propogation framework, the viewpoint of the camera is recovered with high accuracy, and object detection performance improves considerably.
 Recovering Surface Layout from a Single Image
Recovering Surface Layout from a Single Image
We extend our framework from Automatic Photo Pop-up by subclassifying vertical regions, providing extensive quantitative evaluation, and demonstrating the usefulness of the geometric labels as context for object detection.
Our system estimates which regions
of an outdoor image correspond to ground, vertical objects, and sky. These
geometric labels and allow us to construct a coarse 3D model of the scene.
We apply computer vision techniques to identify songs from a short, noisy audio snippet. This research is performed with Yan Ke and Rahul Sukthankar.
 Sound Detection and
Identification
Sound Detection and
Identification
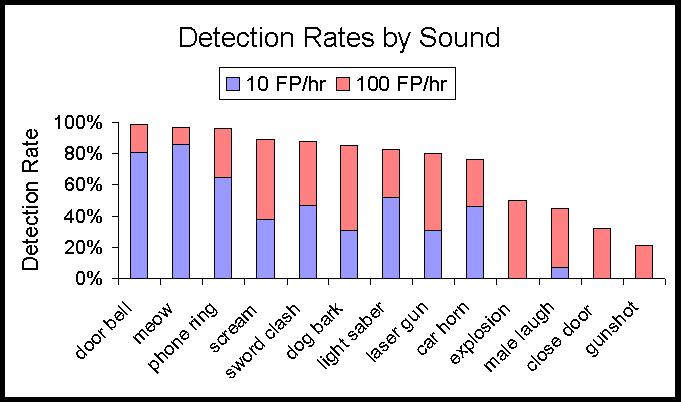
Our goal is to detect and identify sound objects, such as car horns or dog barks, in audio. Our system, called SOLAR (sound object localization and retrieval) is the first, to our knowledge, that is capable of finding a large variety of sounds in audio data from movies and other complex audio environments.
The goal is to retrieve images based
on the appearance of the objects, such as elephants or race cars, contained in
them. Our approach is to extend popular techniques for object detection to be
capable of online training with only a few examples. The key idea is that, once
the underlying statistical structure of the image domain is modeled, that
structure and its parameters can be used to dramatically improve results in a
probabilistic object- based image retrieval system.